Introduction to High Availability and Load Sharing
ClusterXL is a software-based Load Sharing and High Availability solution that distributes network traffic between clusters of redundant Security Gateways.
ClusterXL provides:
- Transparent failover in case of machine failures
- Zero downtime for mission-critical environments (when using State Synchronization)
- Enhanced throughput (in Load Sharing modes)
- Transparent upgrades
All machines in the cluster are aware of the connections passing through each of the other machines. The cluster members synchronize their connection and status information across a secure synchronization network.
The glue that binds the machines in a ClusterXL cluster is the Cluster Control Protocol (CCP), which is used to pass synchronization and other information between the cluster members.
Load Sharing
ClusterXL Load Sharing distributes traffic within a cluster of gateways so that the total throughput of multiple machines is increased.
In Load Sharing configurations, all functioning machines in the cluster are active, and handle network traffic (Active/Active operation).
If any individual Check Point gateway in the cluster becomes unreachable, transparent failover occurs to the remaining operational machines in the cluster, thus providing High Availability. All connections are shared between the remaining gateways without interruption.
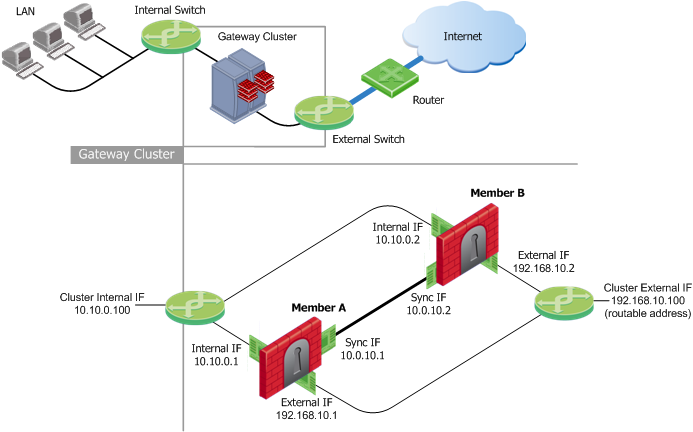
Example ClusterXL Topology
ClusterXL uses unique physical IP and MAC addresses for each cluster member, and a virtual IP addresses for the cluster itself. Cluster interface addresses do not belong to any real machine interface.
The following diagram illustrates a two-member ClusterXL cluster, showing the cluster virtual IP addresses and member physical IP addresses. This sample deployment is used in many of the examples presented in this chapter.
Each cluster member has three interfaces: one external interface, one internal interface, and one for synchronization. Cluster member interfaces facing in each direction are connected via a switch, router, or VLAN switch.
All cluster member interfaces facing the same direction must be in the same network. For example, there must not be a router between cluster members.
The Security Management Server can be located anywhere, and should be routable to either the internal or external cluster addresses.
The following sections present ClusterXL configuration concepts shown in the example.
|
|
2. In the examples in this and subsequent sections, addresses in the range 192.168.0.0to 192.168.255.255 which are RFC 1918 private addresses are used to represent routable (public) IP addresses.
|
Defining the Cluster Member IP Addresses
The guidelines for configuring each cluster member machine are as follows:
All machines within the cluster must have at least three interfaces:
- An interface facing the external cluster interface, which in turn faces the internet.
- An interface facing the internal cluster interface, which in turn faces the internal network.
- An interface to use for synchronization.
All interfaces pointing in a certain direction must be on the same network.
For example, in the previous illustration, there are two cluster members, Member_A and Member_B. Each has an interface with an IP address facing the Internet through a hub or a switch. This is the External interface with IP address 192.168.10.1 on Member_A and 192.168.10.2 on Member_B, and is the interface that the cluster external interface sees.
Defining the Cluster Virtual IP Addresses
In the previous illustration, the IP address of the cluster is 192.168.10.100.
The cluster has one external virtual IP address and one internal virtual IP address. The external IP address is 192.168.10.100, and the internal IP address is 10.10.0.100.
The Synchronization Network
State Synchronization between cluster members ensures that if there is a failover, connections that were handled by the failed machine will be maintained. The synchronization network is used to pass connection synchronization and other state information between cluster members. This network therefore carries all the most sensitive security policy information in the organization, and so it is important to make sure the network is secure. It is possible to define more than one synchronization network for backup purposes.
To secure the synchronization interfaces, they should be directly connected by a cross cable, or in a cluster with three or more members, use a dedicated hub or switch.
Machines in a Load Sharing cluster must be synchronized because synchronization is used in normal traffic flow. Machines in a High Availability cluster do not have to be synchronized, though if they are not, connections may be lost upon failover.
The previous illustration shows a synchronization interface with a unique IP address on each machine. 10.0.10.1 on Member_A and 10.0.10.2 on Member_B.
Configuring Cluster Addresses on Different Subnets
Only one routable IP address is required in a ClusterXL cluster, for the virtual cluster interface that faces the Internet. All cluster member physical IP addresses can be non-routable.
Configuring different subnets for the cluster IP addresses and the member addresses is useful in order to:
- Enable a multi-machine cluster to replace a single-machine gateway in a pre-configured network, without the need to allocate new addresses to the cluster members.
- Allow organizations to use only one routable address for the ClusterXL Gateway Cluster. This saves routable addresses.
ClusterXL Modes
Introduction to ClusterXL Modes
ClusterXL has four working modes. This section briefly describes each mode and its relative advantages and disadvantages.
- Load Sharing Multicast Mode
- Load Sharing Unicast Mode
- New High Availability Mode
- High Availability Legacy Mode
Refer to the High Availability Legacy appendix for a detailed discussion of legacy High Availability functionality. It is recommended that you use the High Availability New Mode to avoid problems with backward compatibility.
|
|
Note - Many examples in the section refer to the sample deployment shown in the ClusterXL example.
|
Load Sharing Multicast Mode
Load Sharing enables you to distribute network traffic between cluster members. In contrast to High Availability, where only a single member is active at any given time, all cluster members in a Load Sharing solution are active, and the cluster is responsible for assigning a portion of the traffic to each member. This assignment is the task of a decision function, which examines each packet going through the cluster, and determines which member should handle it. Thus, a Load Sharing cluster utilizes all cluster members, which usually leads to an increase in its total throughput.
It is important to understand that ClusterXL Load Sharing, when combined with State Synchronization, provides a full High Availability solution as well. When all cluster members are active, traffic is evenly distributed between the machines. In case of a failover event, caused by a problem in one of the members, the processing of all connections handled by the faulty machine is immediately taken over by the other members.
ClusterXL offers two separate Load Sharing solutions: Multicast and Unicast. The two modes differ in the way members receive the packets sent to the cluster. This section describes the Multicast mode.
The Multicast mechanism, which is provided by the Ethernet network layer, allows several interfaces to be associated with a single physical (MAC) address. Unlike Broadcast, which binds all interfaces in the same subnet to a single address, Multicast enables grouping within networks. This means that it is possible to select the interfaces within a single subnet that will receive packets sent to a given MAC address.
ClusterXL uses the Multicast mechanism to associate the virtual cluster IP addresses with all cluster members. By binding these IP addresses to a Multicast MAC address, it ensures that all packets sent to the cluster, acting as a gateway, will reach all members in the cluster. Each member then decides whether it should process the packets or not. This decision is the core of the Load Sharing mechanism: it has to assure that at least one member will process each packet (so that traffic is not blocked), and that no two members will handle the same packets (so that traffic is not duplicated).
An additional requirement of the decision function is to route each connection through a single gateway, to ensure that packets that belong to a single connection will be processed by the same member. Unfortunately, this requirement cannot always be enforced, and in some cases, packets of the same connection will be handled by different members. ClusterXL handles these situations using its State Synchronization mechanism, which mirrors connections on all cluster members.
Example
This scenario describes a user logging from the Internet to a Web server behind the Firewall cluster that is configured in Load Sharing Multicast mode.
- The user requests a connection from 192.168.10.78 (his computer) to 10.10.0.34 (the Web server).
- A router on the 192.168.10.x network recognizes 192.168.10.100 (the cluster's virtual IP address) as the gateway to the 10.10.0.xnetwork.
- The router issues an ARP request to 192.168.10.100.
- One of the active members intercepts the ARP request, and responds with the Multicast MAC assigned to the cluster IP address of 192.168.10.100.
- When the Web server responds to the user requests, it recognizes 10.10.0.100 as its gateway to the Internet.
- The Web server issues an ARP request to 10.10.0.100.
- One of the active members intercepts the ARP request, and responds with the Multicast MAC address assigned to the cluster IP address of 10.10.0.100.
- All packets sent between the user and the Web server reach every cluster member, which decides whether to handle or drop each packet.
- When a failover occurs, one of the cluster members goes down. However, traffic still reaches all of the active cluster members, and hence there is no need to make changes in the network's ARP routing. All that changes is the cluster's decision function, which takes into account the new state of the members.
Load Sharing Unicast Mode
Load Sharing Unicast mode provides a Load Sharing solution adapted to environments where Multicast Ethernet cannot operate. In this mode a single cluster member, referred to as Pivot, is associated with the cluster's virtual IP addresses, and is thus the only member to receive packets sent to the cluster. The pivot is then responsible for propagating the packets to other cluster members, creating a Load Sharing mechanism. Distribution is performed by applying a decision function on each packet, the same way it is done in Load Sharing Multicast mode. The difference is that only one member performs this selection: any non-pivot member that receives a forwarded packet will handle it, without applying the decision function. Note that non-pivot members are still considered as "active", since they perform routing and Firewall tasks on a share of the traffic (although they do not perform decisions.).
Even though the pivot member is responsible for the decision process, it still acts as a Security Gateway that processes packets (for example, the decision it makes can be to handle a packet on the local machine). However, since its additional tasks can be time consuming, it is usually assigned a smaller share of the total load.
When a failover event occurs in a non-pivot member, its handled connections are redistributed between active cluster members, providing the same High Availability capabilities of New High Availability and Load Sharing Multicast. When the pivot member encounters a problem, a regular failover event occurs, and, in addition, another member assumes the role of the new pivot. The pivot member is always the active member with the highest priority. This means that when a former pivot recuperates, it will retain its previous role.
Example
In this scenario, we use a Load Sharing Unicast cluster as the gateway between the user's computer and the Web server.
- The user requests a connection from 192.168.10.78 (his computer) to 10.10.0.34 (the Web server).
- A router on the 192.168.10.x network recognizes 192.168.10.100 (the cluster's virtual IP address) as the gateway to the 10.10.0.xnetwork.
- The router issues an ARP request to 192.168.10.100.
- The pivot member intercepts the ARP request, and responds with the MAC address that corresponds to its own unique IP address of 192.168.10.1.
- When the Web server responds to the user requests, it recognizes 10.10.0.100 as its gateway to the Internet.
- The Web server issues an ARP request to 10.10.0.100.
- The pivot member intercepts the ARP request, and responds with the MAC address that corresponds to its own unique IP address of 10.10.0.1.
- The user's request packet reaches the pivot member on interface 192.168.10.1.
- The pivot decides that the second member should handle this packet, and forwards it to 192.168.10.2.
- The second member recognizes the packet as a forwarded one, and processes it.
- Further packets are processed by either the pivot member, or forwarded and processed by the non-pivot member.
- When a failover occurs on the pivot, the second member assumes the role of pivot.
- The new pivot member sends gratuitous ARP requests to both the 192.168.10.x and the 10.10.0.x networks. These requests associate the virtual IP address of 192.168.10.100 with the MAC address that corresponds to the unique IP address of 192.168.10.2, and the virtual IP address of 10.10.0.100 with the MAC address that correspond to the unique IP address of 10.10.0.2.
- Traffic sent to the cluster is now received by the new pivot, and processed by the local machine (as it is currently the only active machine in the cluster).
- When the first machine recovers, it re-assumes the role of pivot, by associating the cluster IP addresses with its own unique MAC addresses.
High Availability Mode
The High Availability Mode provides basic High-Availability capabilities in a cluster environment. This means that the cluster can provide Firewall services even when it encounters a problem, which on a stand-alone gateway would have resulted in a complete loss of connectivity. When combined with Check Point's State Synchronization, ClusterXL High Availability can maintain connections through failover events, in a user-transparent manner, allowing a flawless connectivity experience. Thus, High-Availability provides a backup mechanism, which organizations can use to reduce the risk of unexpected downtime, especially in a mission-critical environment (such as one involving money transactions over the Internet.)
To achieve this purpose, ClusterXL's New High Availability mode designates one of the cluster members as the active machine, while the other members remain in stand-by mode. The cluster's virtual IP addresses are associated with the physical network interfaces of the active machine (by matching the virtual IP address with the unique MAC address of the appropriate interface). Thus, all traffic directed at the cluster is actually routed (and filtered) by the active member. The role of each cluster member is chosen according to its priority, with the active member being the one with the highest ranking. Member priorities correspond to the order in which they appear in the Cluster Members page of the Gateway Cluster Properties window. The top-most member has the highest priority. You can modify this ranking at any time.
In addition to its role as a Firewall gateway, the active member is also responsible for informing the stand-by members of any changes to its connection and state tables, keeping these members up-to-date with the current traffic passing through the cluster.
Whenever the cluster detects a problem in the active member that is severe enough to cause a failover event, it passes the role of the active member to one of the standby machines (the member with the currently highest priority). If State Synchronization is applied, any open connections are recognized by the new active machine, and are handled according to their last known state. Upon the recovery of a member with a higher priority, the role of the active machine may or may not be switched back to that member, depending on the user's configuration.
It is important to note that the cluster may encounter problems in standby machines as well. In this case, these machines are not considered for the role of active members, in the event of a failover.
Example
This scenario describes a user logging from the Internet to a Web server behind the Firewall cluster.
- The user requests a connection from 192.168.10.78 (his computer) to 10.10.0.34 (the Web server).
- A router on the 192.168.10.x network recognizes
192.168.10.100 (the cluster's virtual IP address) as the gateway to the 10.10.0.x network.
- The router issues an ARP request to 192.168.10.100
.
- The active member intercepts the ARP request, and responds with the MAC address that corresponds to its own unique IP address of 192.168.10.1.
- When the Web server responds to the user requests, it recognizes 10.10.0.100 as its gateway to the Internet.
- The Web server issues an ARP request to 10.10.0.100.
- The active member intercepts the ARP request, and responds with the MAC address that corresponds to its own unique IP address of 10.10.0.1.
- All traffic between the user and the Web server is now routed through the active member.
- When a failover occurs, the standby member concludes that it should now replace the faulty active member.
- The stand-by member sends gratuitous ARP requests to both the 192.168.10.x and the 10.10.0.x networks. These requests associate the virtual IP address of 192.168.10.100 with the MAC address that corresponds to the unique IP address of 192.168.10.2, and the virtual IP address of 10.10.0.100 with the MAC address that correspond to the unique IP address of 10.10.0.2.
- The stand-by member has now switched to the role of the active member, and all traffic directed through the cluster is routed through this machine
- The former active member is now considered to be "down", waiting to recover from whatever problem that had caused the failover event
Mode Comparison Table
This table summarizes the similarities and differences between the ClusterXL modes.
ClusterXL Mode comparison table
|
Legacy High Availability
|
New High Availability
|
Load Sharing Multicast
|
Load Sharing
Unicast
|
|---|
High Availability
|
Yes
|
Yes
|
Yes
|
Yes
|
Load Sharing
|
No
|
No
|
Yes
|
Yes
|
Performance
|
Good
|
Good
|
Excellent
|
Very Good
|
Hardware Support
|
All
|
All
|
Not all routers are supported
|
All
|
SecureXL Support
|
Yes
|
Yes
|
Yes, with Performance Pack or SecureXL Turbocard.
|
Yes
|
State Synchronization Mandatory
|
No
|
No
|
Yes
|
Yes
|
VLAN Tagging Support
|
Yes
|
Yes
|
Yes
|
Yes
|
|
|
Note - For further details regarding VLAN Tagging Support, refer to the R76 Release Notes.
|
Failover
What is a Failover?
A failover occurs when a Gateway is no longer able to perform its designated functions. When this happens another Gateway in the cluster assumes the failed Gateway's responsibilities.
In a Load Sharing configuration, if one Security Gateway in a cluster of gateways goes down, its connections are distributed among the remaining Gateways. All gateways in a Load Sharing configuration are synchronized, so no connections are interrupted.
In a High Availability configuration, if one Gateway in a synchronized cluster goes down, another Gateway becomes active and "takes over" the connections of the failed Gateway. If you do not use State Synchronization, existing connections are closed when failover occurs, although new connections can be opened.
To tell each cluster member that the other gateways are alive and functioning, the ClusterXL Cluster Control Protocol maintains a heart beat between cluster members. If a certain predetermined time has elapsed and no message is received from a cluster member, it is assumed that the cluster member is down and a failover occurs. At this point another cluster member automatically assumes the responsibilities of the failed cluster member.
It should be noted that a cluster machine may still be operational but if any of the above checks fail in the cluster, then the faulty member initiates the failover because it has determined that it can no longer function as a cluster member.
Note that more than one cluster member may encounter a problem that will result in a failover event. In cases where all cluster members encounter such problems, ClusterXL will try to choose a single member to continue operating. The state of the chosen member will be reported as Active Attention. This situation lasts until another member fully recovers. For example, if a cross cable connecting the cluster members malfunctions, both members will detect an interface problem. One of them will change to the Downstate, and the other to Active Attention.
When Does a Failover Occur?
A failover takes place when one of the following occurs on the active cluster member:
- Any critical device (such as fwd) fails. A critical device is a process running on a cluster member that enables the member to notify other cluster members that it can no longer function as a member. The device reports to the ClusterXL mechanism regarding its current state or it may fail to report, in which case ClusterXL decides that a failover has occurred and another cluster member takes over.
- An interface or cable fails.
- The machine crashes.
- The Security Policy is uninstalled. When the Security Policy is uninstalled the Gateway can no longer function as a firewall. If it cannot function as a firewall, it can no longer function as a cluster member and a failover occurs. Normally a policy is not uninstalled by itself but would be initiated by a user. For more on failovers, see sk62570.
What Happens When a Gateway Recovers?
In a Load Sharing configuration, when the failed Gateway in a cluster recovers, all connections are redistributed among all active members.
In a High Availability configuration, when the failed Gateway in a cluster recovers, the recovery method depends on the configured cluster setting. The options are:
- Maintain Current Active Gateway means that if one machine passes on control to a lower priority machine, control will be returned to the higher priority machine only if the lower priority machine fails. This mode is recommended if all members are equally capable of processing traffic, in order to minimize the number of failover events.
- Switch to Higher Priority Gateway means that if the lower priority machine has control and the higher priority machine is restored, then control will be returned to the higher priority machine. This mode is recommended if one member is better equipped for handling connections, so it will be the default gateway.
How a Recovered Cluster Member Obtains the Security Policy
The administrator installs the security policy on the cluster rather than separately on individual cluster members. The policy is automatically installed on all cluster members. The policy is sent to the IP address defined in the General Properties page of the cluster member object.
When a failed cluster member recovers, it will first try to take a policy from one of the other cluster members. The assumption is that the other cluster members have a more up to date policy. If this does not succeed, it compares its own local policy to the policy on the Security Management server. If the policy on the Security Management server is more up to date than the one on the cluster member, the policy on the Security Management server will be retrieved. If the cluster member does not have a local policy, it retrieves one from the Security Management server. This ensures that all cluster members use the same policy at any given moment.
Implementation Planning Considerations
High Availability or Load Sharing
Whether to choose a Load Sharing (Active/Active) or a High Availability (Active/Standby) configuration depends on the need and requirements of the organization. A High Availability gateway cluster ensures fail-safe connectivity for the organization. Load Sharing provides the additional benefit of increasing performance.
|
|
Note - When working on a sync network, it is recommended to use a NIC with the same bandwidth as the NICs that are used for general traffic.
|
Choosing the Load Sharing Mode
Load Sharing Multicast mode is an efficient way to handle a high load because the load is distributed optimally between all cluster members. However, not all routers can be used for Load Sharing Multicast mode. Load Sharing Multicast mode associates a multicast MAC with each unicast cluster IP address. This ensures that traffic destined for the cluster is received by all members. The ARP replies sent by a cluster member will therefore indicate that the cluster IP address is reachable via a multicast MAC address.
Some routing devices will not accept such ARP replies. For some routers, adding a static ARP entry for the cluster IP address on the routing device will solve the issue. Other routers will not accept this type of static ARP entry.
Another consideration is whether your deployment includes routing devices with interfaces operating in promiscuous mode. If on the same network segment there exists two such routers and a ClusterXL gateway in Load Sharing Multicast mode, traffic destined for the cluster that is generated by one of the routers could also be processed by the other router.
For these cases, use Load Sharing Unicast mode, which does not require the use of multicast for the cluster addresses.
IP Address Migration
If you wish to provide High Availability or Load Sharing to an existing single gateway configuration, it is recommended to take the existing IP addresses from the current gateway, and make these the cluster addresses (cluster virtual addresses), when feasible. Doing so will avoid altering current IPSec endpoint identities, as well keep Hide NAT configurations the same in many cases.
Hardware Requirements, Compatibility and Cisco Example
ClusterXL Hardware Requirements
The Gateway Cluster is usually located in an environment having other networking devices such as switches and routers. These devices and the Gateways must interact to assure network connectivity. This section outlines the requirements imposed by ClusterXL on surrounding networking equipment.
HA New and Load Sharing Unicast Modes
Multicast mode is the default Cluster Control Protocol (CCP) mode in High Availability New Mode and Load Sharing Unicast Mode (and also Load Sharing Multicast Mode).
When using CCP in multicast mode, configure the following settings on the switch.
Switch Setting for High Availability New Mode and Load Sharing
Switch Setting
|
Explanation
|
|---|
IGMP and Static CAMs
|
ClusterXL does not support IGMP registration (also known as IGMP Snooping) by default. Either disable IGMP registration in switches that rely on IGMP packets to configure their ports, or enable IGMP registration on ClusterXL. In situations where disabling IGMP registration is not acceptable, it is necessary to configure static CAMs in order to allow multicast traffic on specific ports.
|
Disabling multicast limits
|
Certain switches have an upper limit on the number of broadcasts and multicasts that they can pass, in order to prevent broadcast storms. This limit is usually a percentage of the total interface bandwidth.
It is possible to either turn off broadcast storm control, or to allow a higher level of broadcasts or multicasts through the switch.
If the connecting switch is incapable of having any of these settings configured, it is possible, though less efficient, for the switch to use broadcast to forward traffic, and to configure the cluster members to use broadcast CCP.
|
Configure the following settings on the router:
Router Setting for High Availability New Mode and Load Sharing Unicast Mode
Router Setting
|
Explanation
|
|---|
Unicast MAC
|
When working in High Availability Legacy mode, High Availability New mode and Load Sharing Unicast mode, the Cluster IP address is mapped to a regular MAC address, which is the MAC address of the active member. The router needs to be able to learn this MAC through regular ARP messages.
|
Virtual MAC mode - VMAC
When the ClusterXL product is configured in HA mode or load-sharing unicast mode (not multicast) a single cluster member is associated with the Cluster's Virtual IP address. In a High Availability environment, the single member is the active member. In a load-sharing environment, the single member is the pivot.
After fail-over, the new active member (or pivot member) broadcasts a series of Gratuitous ARP Requests (G-ARPs). The G-ARPS associate the Virtual IP address of the cluster with the physical MAC address of the new active member or the new pivot. When this happens:
- A member with a large number of Static NAT entries can transmit too many G-ARPS
Switches may not integrate these G-ARP updates quickly enough into their ARP tables. Switches continue to send traffic to the physical MAC address of the member that failed. This results in traffic outage until the switches have fully updated ARP cache tables.
- Network components such as VoIP phones ignore the G-ARPs
These components continue to send traffic to the MAC address of the failed member.
To minimize possible traffic outage during a fail-over, configure the cluster to use a virtual MAC address (VMAC).
By enabling Virtual MAC in ClusterXL High Availability mode, or Load Sharing Unicast mode, all cluster members associate the same Virtual MAC address with all Cluster Virtual Interfaces and the Virtual IP address. In Virtual MAC mode, the VMAC that is advertised by the cluster members (through G-ARP Requests) keeps the real MAC address of each member and adds a Virtual MAC address on top of it.
(For local connections and sync connections, the real MAC address of each member is still associated with its real IP address.)
|
|
Note - VMAC mode is supported only on SecurePlatform and Gaia.
- In SecurePlatform, VMAC is enabled through the command line only
- In Gaia, VMAC is enabled through the command line or SmartDashboard
|
VMAC failover time is shorter than a failover that involves a physical MAC address.
To configure VMAC Mode using SmartDashboard (R76 and higher):
- Double-click the Cluster object to open its window.
- On the page, select .
- Install a policy.
To configure VMAC Mode using the command line:
Set the value of global kernel parameter fwha_vmac_global_param_enabled.
- First get the current value of global kernel parameter by running this command on a cluster member:
fw ctl get int fwha_vmac_global_param_enabled
- Set the new value by running:
fw ctl set int fwha_vmac_global_param_enabled VALUE
Where:
VALUE
|
Description
|
|---|
1
|
VMAC enabled
|
0
|
VMAC disabled
|
- Make sure VMAC mode is enabled by running:
cphaprob -a if
The command shows the VMAC address of each virtual cluster interface.
|
|
Note -
- On SecurePlatform this command has to be run in Expert shell.
- On Gaia this command can be run in Clish or Bash.
|
For more on VMAC mode, see: sk50840
To set the VMAC mode value permanently, see the sk on changing kernel global parameters: sk26202
Load Sharing Multicast Mode
When working in Load Sharing Multicast mode, the switch settings are as follows:
Switch Configuration for Load Sharing Multicast Mode
Switch Setting
|
Explanation
|
|---|
CCP in Multicast mode
|
Multicast mode is the default Cluster Control Protocol mode in Load Sharing Multicast.
|
Port Mirroring
|
ClusterXL does not support the use of unicast MAC addresses with Port Mirroring for Multicast Load Sharing solutions.
|
When working in Load Sharing Multicast mode, the router must support sending unicast IP packets with Multicast MAC addresses. This is required so that all cluster members will receive the data packets.
The following settings may need to be configured in order to support this mode, depending on the model of the router:
Router Configuration for Load Sharing Multicast Mode
Router Setting
|
Explanation
|
|---|
Static MAC
|
Most routers can learn ARP entries with a unicast IP and a multicast MAC automatically using the ARP mechanism. If you have a router that is not able to learn this type of mapping dynamically, you'll have to configure static MAC entries.
|
IGMP and static cams
|
Some routers require disabling of IGMP snooping or configuration of static cams in order to support sending unicast IP packets with Multicast MAC addresses.
|
Disabling multicast limits
|
Certain routers have an upper limit on the number of broadcasts and multicasts that they can pass, in order to prevent broadcast storms. This limit is usually a percentage of the total interface bandwidth.
It is possible to either turn off broadcast storm control, or to allow a higher level of broadcasts or multicasts through the router.
|
Disabling forwarding multicast traffic to the router
|
Some routers will send multicast traffic to the router itself. This may cause a packet storm through the network and should be disabled.
|
ClusterXL Hardware Compatibility
The following routers and switches are known to be compatible for all ClusterXL modes:
Routers
- Cisco 7200 Series
- Cisco 1600, 2600, 3600 Series
Routing Switch
- Extreme Networks Blackdiamond (Disable IGMP snooping)
- Extreme Networks Alpine 3800 Series (Disable IGMP snooping)
- Foundry Network Bigiron 4000 Series
- Nortel Networks Passport 8600 Series
- Cisco Catalyst 6500 Series (Disable IGMP snooping, Configure Multicast MAC manually)
Switches
- Cisco Catalyst 2900, 3500 Series
- Nortel BayStack 450
- Alteon 180e
- Dell PowerConnect 3248 and PowerConnect 5224
Example Configuration of a Cisco Catalyst Routing Switch
The following example shows how to perform the configuration commands needed to support ClusterXL on a Cisco Catalyst 6500 Series routing switch. For more details, or instructions for other networking devices, please refer to the device vendor documentation.
Disabling IGMP Snooping
To disable IGMP snooping run:
no ip igmp snooping
Defining Static Cam Entries
To add a permanent multicast entry to the table for module 1, port 1, and module 2, ports 1, 3, and 8 through 12:
- Console> (enable) set cam permanent 01-40-5e-28-0a-64 1/1,2/1,2/3,2/8-12
- Permanent multicast entry added to CAM table.
- Console> (enable)
To determine the MAC addresses which needs to be set:
- On a network that has a cluster IP address of x.y.z.w :
- If y<=127, the multicast MAC address would be 01:00:5e:y:z:w. For example: 01:00:5e:5A:0A:64 for 192.90.10.100
- If y>127, the multicast MAC address would be 01:00:5e:(y-128):z:w. For example: 01:00:5e:28:0A:64 for 192.168.10.100 (168-128=40 = 28 in hex).
- For a network x.y.z.0 that does not have a cluster IP address, such as the sync, you would use the same procedure, and substitute fa instead of 0 for the last octet of the MAC address.
- For example: 01:00:5e:00:00:fa for the 10.0.0.X network.
Disabling Multicast Limits
To disable multicast limits run:
no storm-control multicast level
Configuring a Static ARP Entry on the Router
To define a static ARP entry:
- Determine the MAC address.
- Run
arp <MAC address> arpa
Disabling Multicast Packets from Reaching the Router
To prevent multicast packets from reaching the router:
- Determine the MAC address.
- Run
set cam static <MAC address> module/port.
Check Point Software Compatibility
Operating System Compatibility
The operating systems listed in the table below are supported by ClusterXL, with the limitations listed in the notes below. For details on the supported versions of these operating systems, refer to the R76 Release Notes.
ClusterXL Operating System Compatibility
Operating System
|
Load Sharing
|
High Availability
|
|---|
Check Point SecurePlatform
|
Yes
|
Yes
|
Notes
1. VLANs are supported on all interfaces.
ClusterXL Compatibility (Excluding IPS)
The following table and accompanying notes present ClusterXL Load Sharing and High Availability compatibility for OPSEC Certified cluster products. Some Check Point products and features are not supported or are only partially supported (as detailed in the footnotes) for use with ClusterXL.
Products and features that are not fully supported with ClusterXL
Feature or Product
|
Feature
|
Load Sharing
|
High Availability
|
|---|
Security Management
|
|
No
|
No
|
Firewall
|
Authentication/Security Servers
|
Yes (1)
|
Yes (1)
|
Firewall
|
ACE servers and SecurID
|
Yes
|
Yes
|
Firewall
|
Application Intelligence protocol inspection (2)
|
Yes (3)
|
Yes
|
Firewall
|
Sequence Verifier
|
Yes (4)
|
Yes (1)
|
Firewall
|
UDP encapsulation
|
Yes
|
Yes
|
Firewall
|
SAM
|
Yes
|
Yes
|
Firewall
|
ISP Redundancy
|
Yes
|
Yes
|
VPN
|
Third party VPN peers
|
Yes
|
Yes
|
Endpoint Security Client
|
Software Distribution Server (SDS)
|
No
|
No
|
Endpoint Security Client
|
IP per user in Office Mode
|
Yes
|
Yes
|
SecureXL hardware acceleration or Performance Pack
|
|
Yes
|
Yes
|
Check Point QoS
|
|
Yes (4)(5)
|
Yes
|
SmartProvisioning
|
SmartLSM Security Gateway
|
No
|
No
|
Check Point Security Gateway
|
|
Yes
|
Yes
|
- If there is a failover when fragments are being received, the packet will be lost.
- Does not survive failover.
- Requires unidirectional stickiness. This means that the same member must receive all external packets, and the same member must receive all internal packets, but the same member does not have to receive both internal and external packets.
- Requires bidirectional connection stickiness.
- Uses the forwarding layer, described in the next section.
ClusterXL Compatibility with IPS
The following IPS features are supported by ClusterXL, with the limitations listed in the notes.
ClusterXL Compatibility with IPS
Feature
|
Load Sharing
|
High Availability
|
|---|
Fragment Sanity Check
|
Yes (1, 3)
|
Yes (1)
|
Pattern Matching
|
Yes (2, 3)
|
Yes (2)
|
Sequence Verifier
|
Yes (2, 4)
|
Yes (2)
|
FTP, HTTP and SMTP Security Servers
|
Yes (2, 5)
|
Yes (2)
|
- If there is a failover when fragments are being received, the packet will be lost.
- Does not survive failover.
- Requires unidirectional stickiness. This means that the same member must receive all external packets, and the same member must receive all internal packets, but the same member does not have to receive both internal and external packets.
- Requires bidirectional connection stickiness.
- Uses the forwarding layer, described in the next section.
Footnotes
- If there is a failover when fragments are being received, the packet will be lost.
- Does not survive failover.
- Requires unidirectional stickiness. This means that the same member must receive all external packets, and the same member must receive all internal packets, but the same member does not have to receive both internal and external packets.
- Requires bidirectional connection stickiness.
- Uses the forwarding layer, described in the next section.
Forwarding Layer
The Forwarding Layer is a ClusterXL mechanism that allows a cluster member to pass packets to other members, after they have been locally inspected by the Firewall. This feature allows connections to be opened from a cluster member to an external host.
Packets originated by cluster members are hidden behind the cluster's virtual IP. Thus, a reply from an external host is sent to the cluster, and not directly to the source member. This can pose problems in the following situations:
- The cluster is working in New High Availability mode, and the connection is opened from the stand-by machine. All packets from the external host are handled by the active machine, instead.
- The cluster is working in a Load Sharing mode, and the decision function has selected another member to handle this connection. This can happen since packets directed at a cluster IP are distributed among cluster members as with any other connection.
If a member decides, upon the completion of the Firewall inspection process, that a packet is intended for another cluster member, it can use the Forwarding Layer to hand the packet over to that destination. This is done by sending the packet over a secured network (any subnet designated as a Synchronization network) directly to that member. It is important to use secured networks only, as encrypted packets are decrypted during the inspection process, and are forwarded as clear-text (unencrypted) data.
Packets sent on the Forwarding Layer use a special source MAC address to inform the receiving member that they have already been inspected by another Security Gateway. Thus, the receiving member can safely hand over these packets to the local Operating System, without further inspection. This process is secure, as Synchronization Networks should always be isolated from any other network (using a dedicated network).
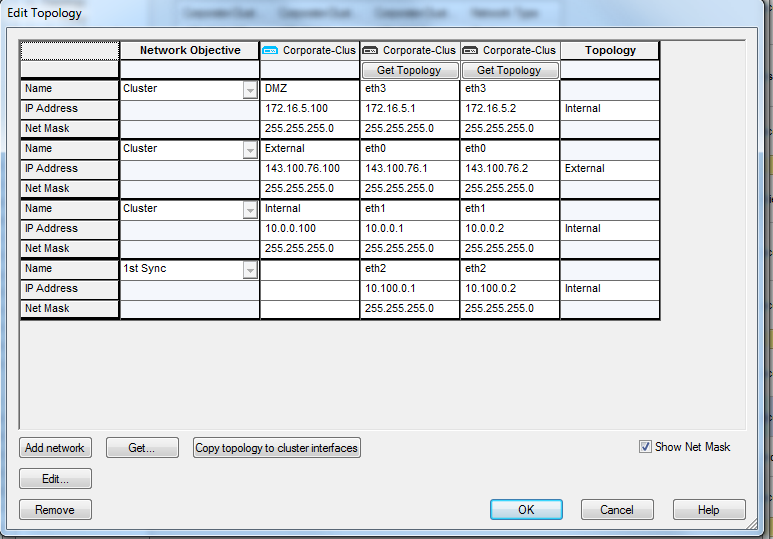
Configuring the Cluster Topology
- In the Topology page, click Edit Topology to define the virtual cluster IP addresses and at least one synchronization network.
- In the Edit Topology window:
- Define the topology for each member interface. To automatically read all predefined settings on member interfaces, click Copy topology to cluster interfaces.
In the Network Objective column, select an objective for each network from the list. The various options are explained in the online help. To define a new network, click Add Network.
- Define the topology for each virtual cluster interface. In a virtual cluster interface cell, right click and select Edit Interface. The Interface Properties window opens.
- In the General tab, Name the virtual interface, and define an IP Address.
- In the Topology tab, define whether the interface is internal or external, and set up anti-spoofing.
If you select:
- and
- contains a group, then:
The group must contain the Sync IP addresses of all the members.
- In the Member Networks tab, define the member network and net mask if necessary. This advanced option is explained in Configuring Cluster Addresses on Different Subnets.
|